Tokens
The AI mechanism operates on the principle of maximum probability. For example, if you ask a model to complete the sentence “Love, love me do…”, it will review all the sentences it was trained on, as well as those on the internet, conclude that since there is a Beatles song, it will choose the completion “…you know I love you” with a certain higher percentage of probability.
Our prompt, or request, is broken down into so-called tokens, which are parts of words. Each token has an ID number that is sent to the model (the “brain”), located in some data center somewhere in the world. Ordinary short words often become a single token, while longer words and compounds are typically split into multiple tokens.
The average length of one token in the English language is 0.75 of the average word length. The complete works of Shakespeare have about 900,000 words, or about 1.2 million tokens.
In the following image, in the colored section at the bottom, we can see how words are divided into tokens. Each of these pieces has its own ID number.
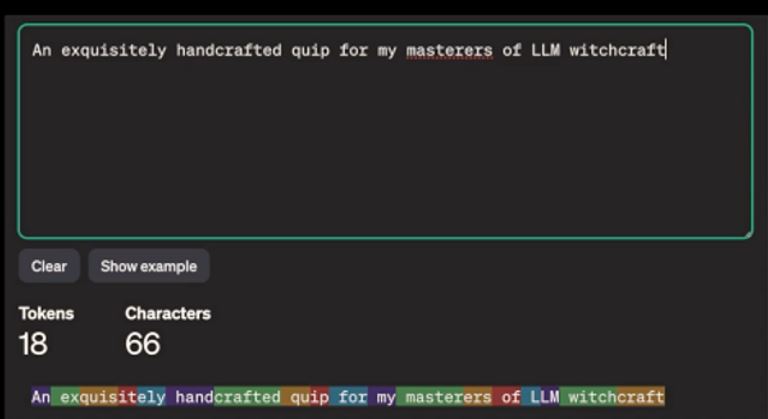
So, when we send a query to the model for processing, we are not sending the question in the form a human would understand or as it appears on the screen. Instead, we send a burst of numbers with the request: “Complete this sequence with the numbers of the highest probability.”
If we send the greeting “Hi, my name is Ed” to the model from our code or from a chatbot, what it receives is a sequence of numbers. The sentence in parentheses below is encoded – translated into a sequence of numbers to the right of the equals sign – and that sequence is entered on the left under “tokens.”

The variable “tokens” now contains the sequence of token identification numbers:

Tone and creativity
When we send a question to the model, it usually consists of two parts:
- System prompt – which defines the model’s role, its perspective, and the manner of responding.
- User prompt – where we ask the question. In the example below, we told it: “You are Karen, who irritates people and gets easily offended.” Because this character is widely known and present on the internet, the model “understands” the broader context and the character it is supposed to “portray.”
We then asked where the nearest store is.
The chatbot’s response was roughly: “Are you trying to say I don’t know my own neighborhood or don’t know how to use navigation? That’s very insulting to underestimate someone’s ability like that! It’s the 21st century! I demand a little more respect!”
From this, we can see that, on the other hand, the creators of models can use this technique to determine the chatbot’s “personality,” the tone and direction of its responses, and its degree of imagination or dryness.
So, the chatbot responds with absolutely no information, shaping the answer entirely with the requested tone and style. Notice in the code above the parameter “temperature,” which we set to 0.7. The closer this parameter is to 1, the more “creative” the response will be. So, if we are writing an official email or a legal text, it’s best to set the temperature to 0; if we want it to come up with a children’s bedtime story with specified characters, then it can be set to 0.9 or 1.

Leave a Reply